Nium Resources Hub

Explore Our Content


Nium announces global payments expansion in Indonesia; adds to recent successes in Korea and Thailand


Read this paper to learn more about the challenges and opportunities for cross-border payments in APAC.

May 6 - 9, 2024
Reach new markets and grow your business with the leading platform for real-time global payments

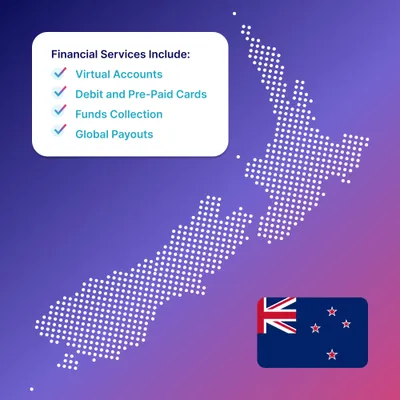
Nium, the global leader in real-time, cross-border payments, today announced it is now registered as a Financial Services Provider in New Zealand.


The Fintech Marketing Hub, in partnership with Innovate Finance, released its 4th edition of “Fintech’s 30 Most Influential Marketers.” The list celebrates marketing excellence and innovation, with honorees from globally renowned fintech brands.
Premium content
Breaking Borders: The Revolution of Real-Time Cross-Border B2B Payments in Asia In Partnership with Kapronasia

Premium content
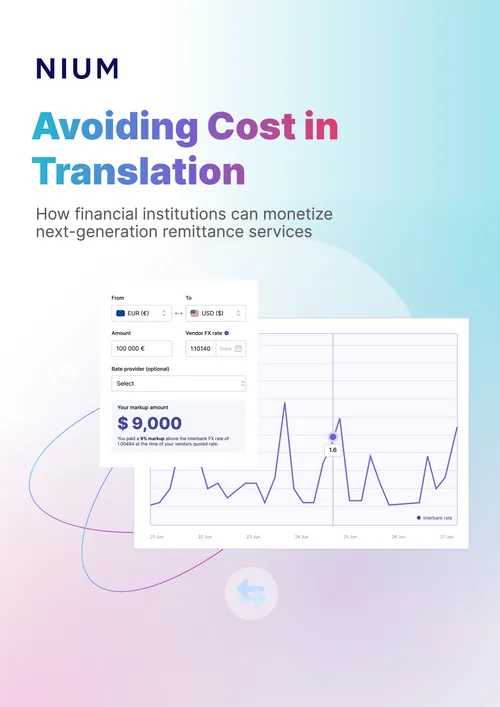
Avoiding Cost in Translation
Premium content
Fearless FX: Currency Exchange to Drive Global Growth